Human Detection¶
Here we would see how we can use computer vision to carry out the task of human or pedestrian detection.
OpenCV has a built-in pre-trained HOG + Linear SVM model that can be used to perform human detection in both images and video streams. We implement the non-maxima suppression (NMS) algorithm which in short takes multiple, overlapping bounding boxes and reduces them to only a single bounding box; so as to reduce the number of false-positives reported by the final object detector. The following code performs the task of pedestrian detection:
# import the necessary packages
from __future__ import print_function
from imutils.object_detection import non_max_suppression
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
# initialize the HOG descriptor/person detector
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
# loop over the image paths
imagePaths = list(paths.list_images("images"))
for imagePath in imagePaths:
# load the image and resize it to (1) reduce detection time
# and (2) improve detection accuracy
image = cv2.imread(imagePath)
image = imutils.resize(image, width=min(400, image.shape[1]))
orig = image.copy()
# detect people in the image
(rects, weights) = hog.detectMultiScale(image, winStride=(4, 4),
padding=(8, 8), scale=1.05)
# draw the original bounding boxes
for (x, y, w, h) in rects:
cv2.rectangle(orig, (x, y), (x + w, y + h), (0, 0, 255), 2)
# apply non-maxima suppression to the bounding boxes using a
# fairly large overlap threshold to try to maintain overlapping
# boxes that are still people
rects = np.array([[x, y, x + w, y + h] for (x, y, w, h) in rects])
pick = non_max_suppression(rects, probs=None, overlapThresh=0.65)
# draw the final bounding boxes
for (xA, yA, xB, yB) in pick:
cv2.rectangle(image, (xA, yA), (xB, yB), (0, 255, 0), 2)
# show some information on the number of bounding boxes
filename = imagePath[imagePath.rfind("/") + 1:]
print("[INFO] {}: {} original boxes, {} after suppression".format(
filename, len(rects), len(pick)))
# show the output images
cv2.imshow("Before NMS", orig)
cv2.imshow("After NMS", image)
cv2.waitKey(0)
First after importing the required modules and loading our folder that contains the pedestrian images, we initialize our pedestrian detector. We make a call to hog = cv2.HOGDescriptor() which initializes the Histogram of Oriented Gradients descriptor. Then, we call the setSVMDetector to set the Support Vector Machine to be pre-trained pedestrian detector, loaded via the cv2.HOGDescriptor_getDefaultPeopleDetector() function.
We loop over the images in our images directory. You can download the datset of images with pedestrian from the popular INRIA Person Dataset (specifically, from the GRAZ-01 subset).
From there, we handle loading our image off disk and resizing it to have a maximum width of 400 pixels. We reduce our image dimensions because:
- Reducing image size ensures that less sliding windows in the image pyramid need to be evaluated (i.e., have HOG features extracted from and then passed on to the Linear SVM), thus reducing detection time (and increasing overall detection throughput).
- Resizing our image also improves the overall accuracy of our pedestrian detection (i.e., less false-positives).
We use the detectMultiScale method of the HOG descriptor that constructs an image pyramid with scale=1.05 and a sliding window step size of (4, 4) pixels in both the x and y direction respectively. The size of the sliding window is fixed at 32 x 128 pixels. The detectMultiScale function returns a 2-tuple of rects , or the bounding box (x, y)-coordinates of each person in the image, and weights , the confidence value returned by the SVM for each detection.
A larger scale size will evaluate less layers in the image pyramid which can make the algorithm faster to run. However, having too large of a scale (i.e., less layers in the image pyramid) can lead to pedestrians not being detected. Similarly, having too small of a scale size dramatically increases the number of image pyramid layers that need to be evaluated. Not only can this be computationally expecnsive, it can also increase the number of false-positives detected by the pedestrian detector.
Then we take our initial bounding boxes and draw them on our image. However, for some images you’ll notice that there are multiple, overlapping bounding boxes detected for each person. In this case, we have two options. We can detect if one bounding box is fully contained within another. Or we can apply non-maxima suppression and suppress bounding boxes that overlap with a significant threshold.
After applying non-maxima suppression, we draw the finalized bounding boxes, display some basic information about the image and number of bounding boxes, and finally display our output images to our screen.
The resulting output before and after non-maximum suppression of two sample images from the dataset looks like:
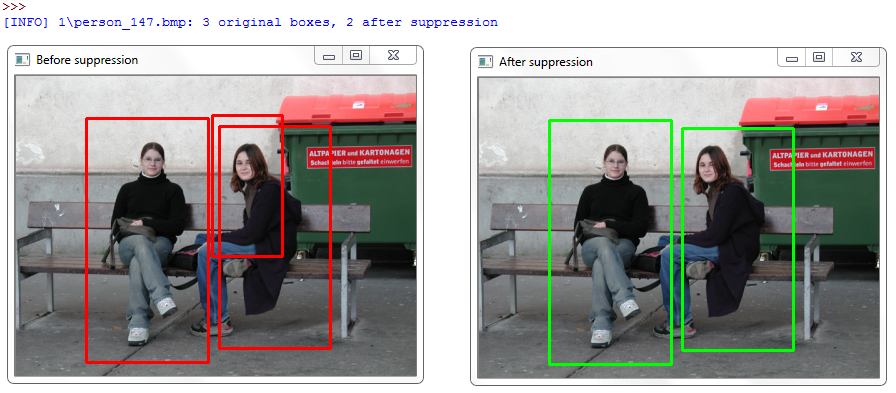
The above image serves an example of why applying non-maxima suppression is important. The detectMultiScale function falsely detected two bounding boxes (along with the correct bounding box), both overlapping the true person in the image. By applying non-maxima suppression we were able to suppress the extraneous bounding boxes, leaving us with the true detection
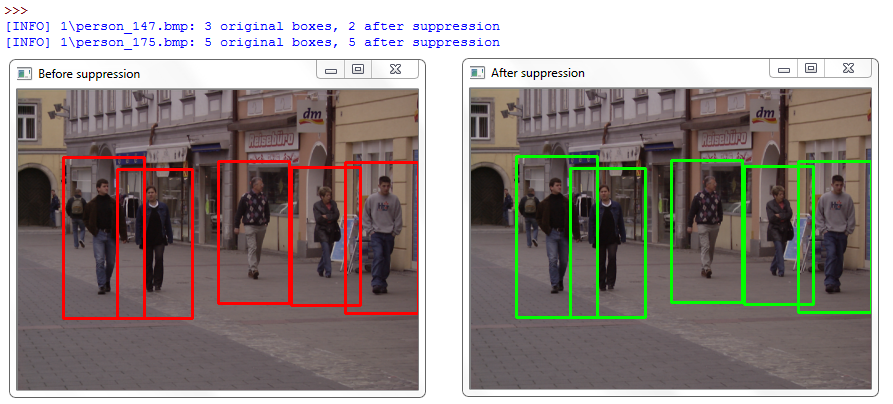
Here our HOG method is able to detect the people. The larger overlapThresh in the non_maxima_suppression function ensures that the bounding boxes are not suppressed, even though they do partially overlap.